Step by Step Toward Safe Autonomous Driving
Freiburg, Dec 13, 2021
The computer scientist Prof. Dr. Abhinav Valada is using artificial intelligence (AI) in several research projects to teach self-driving cars to quickly recognize their environment and other road users. He and his team demonstrate this capability with colorful images and videos how cars use cameras and LiDARs (light detection and ranging), a form of three-dimensional laser scanning, to identify their surroundings while driving.
 In the LiDAR panoptic segmentation output from the latest EfficientLPS AI model, each 3D point is assigned a unique color depending on the object class to which it belongs. For example LiDAR points on the road are denoted in magenta and buildings are blue.
In the LiDAR panoptic segmentation output from the latest EfficientLPS AI model, each 3D point is assigned a unique color depending on the object class to which it belongs. For example LiDAR points on the road are denoted in magenta and buildings are blue.
The road is purple, cars are blue, and pedestrians are red. What would otherwise be a normal car ride through the city suddenly look unfamiliar through the eyes of artificial intelligence (AI). The colorful images produced by the AI created by Prof. Dr. Abhinav Valada, Assistant Professor of Robot Learning in the Department of Computer Science of the University of Freiburg, demonstrates this capability. While driving, the artificial intelligence recognizes which pixels in the video belong to which type of object in the environment and simultaneously identifies distinct individual instances of objects. This enables the AI to establish which road users are near and how the urban scene in the background looks. This process is called panoptic segmentation and is an important component for smooth autonomous driving. It can also be used for other applications. “All types of robots must first understand the world around them. It’s only when they’re able to recognize objects and categorize them that they can fulfill other tasks,” says Valada. This is why the method of panoptic segmentation is important not just in this field, but in other fields of robotics and in medical applications.
The AI learns scene understanding through deep learning
Panoptic segmentation combines semantic segmentation with instance segmentation. While in semantic segmentation, each pixel of an image is associated with a class of objects, instance segmentation combines pixel groups into individual objects and delineates them. “Combining these methods results in the AI being able to distinguish between the individual actors and/or instances in road traffic and to count them,” explains Valada. This means the AI is not only aware that there are cars in front of it; it also recognizes that there are several individual cars.
The AI acquires this scene understanding with the help of what is known as deep learning, a type of machine learning in which artificial neural networks inspired by the human brain learn from large amounts of data. The researchers at the University of Freiburg feed their AI thousands upon thousands of images of traffic situations to teach it what it must recognize in each image. “We are training it with images that are as diverse as possible,” says Valada, “because that way the AI is better able to classify what it has not seen before.”
This training worked very well with the team’s EfficientPS model. In this project, a car that learned only from images from Stuttgart also recognizes all objects when driving in Freiburg. With EfficientPS, the researchers from the University of Freiburg secured the first place in the Cityscapes benchmark, which Valada says is possibly the most influential public benchmark for visual scene understanding methods in autonomous driving. Benchmarks such as these are used to rank the performance of different artificial intelligence algorithms. “Many methods require large amounts of data and therefore too much processing power. Our method is the most efficient and fastest in this respect,” says Valada.
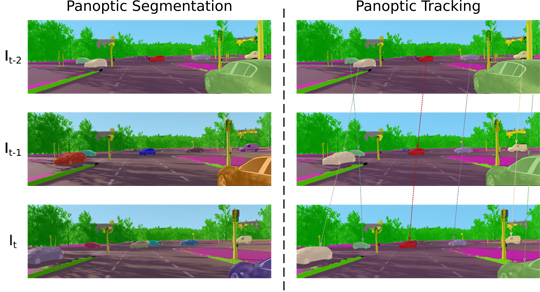 The Multi-Object Panoptic Tracking (MOPT) combines panoptic segmentation and object tracking. Here, the same object instances are tracked across the video frames. They are assigned the same color to indicate whether they are the same object that was previously detected.
The Multi-Object Panoptic Tracking (MOPT) combines panoptic segmentation and object tracking. Here, the same object instances are tracked across the video frames. They are assigned the same color to indicate whether they are the same object that was previously detected.
Valada and his team are working on a similar model called EfficientLPS as well, using LiDAR or laser reflections instead of camera images. Unlike camera images, which are only useable in good weather, laser beams can also scan the surroundings and recreate their structure when there are challenging illumination conditions. This means EfficientLPS learns from 3D information instead of images. With their EfficientLPS model the team around Valada secured the first place in the SemanticKITTI benchmark, which is one of the most popular benchmarks for LiDAR scene understanding. In collaboration with an autonomous vehicle company, Motional, Valada's team has also recently released a new dataset for LiDAR scene understanding: the Panoptic nuScenes dataset. "It consists of many dynamic agents such as vehicles, cyclists and pedestrians, much more than in existing datasets, making it the largest and most diverse dataset to date for understanding urban scenes," Valada says.
“A step towards a more holistic understanding of scenes, similar to the ability of humans”
In addition, the researchers realized their latest model "MOPT", which stands for Multi-Object Panoptic Tracking, following on from the EfficientPS and EfficientLPS models. They have taught this AI to also track the movement of individual objects while driving. It therefore not only recognizes what the objects are in the environment and how many objects are there, it also associates the objects across the video frames. That is, it indicates how the objects move in the environment with time and if an object that we saw before is the same one that we see a few seconds later. MOPT is the first attempt in the world to unify panoptic segmentation and multi-object tracking. Creating an AI that learns these tasks jointly improves the overall efficiency and makes it easier to deploy them in robots. “This is a step towards a more holistic understanding of scenes, similar to the ability of humans,” says Valada.
Valada’s area of research incorporates only a fraction of what is required for safe autonomous driving, and it will still take some time before people can completely trust self-driving cars. As Valada says, “The real challenge is to make cars really safe, so that they can react in unexpected and difficult situations in the right way. And we have to solve the ethical issues as well, of course.”
Franziska Becker
Pressemitteilung zum Modell „EfficientPS“
Contact:
Prof. Dr. Abhinav Valada
Robot Learning Lab
University of Freiburg
Phone: +49 (0) 761 203–8025
E-Mail: valada@cs.uni-freiburg.de